graphster

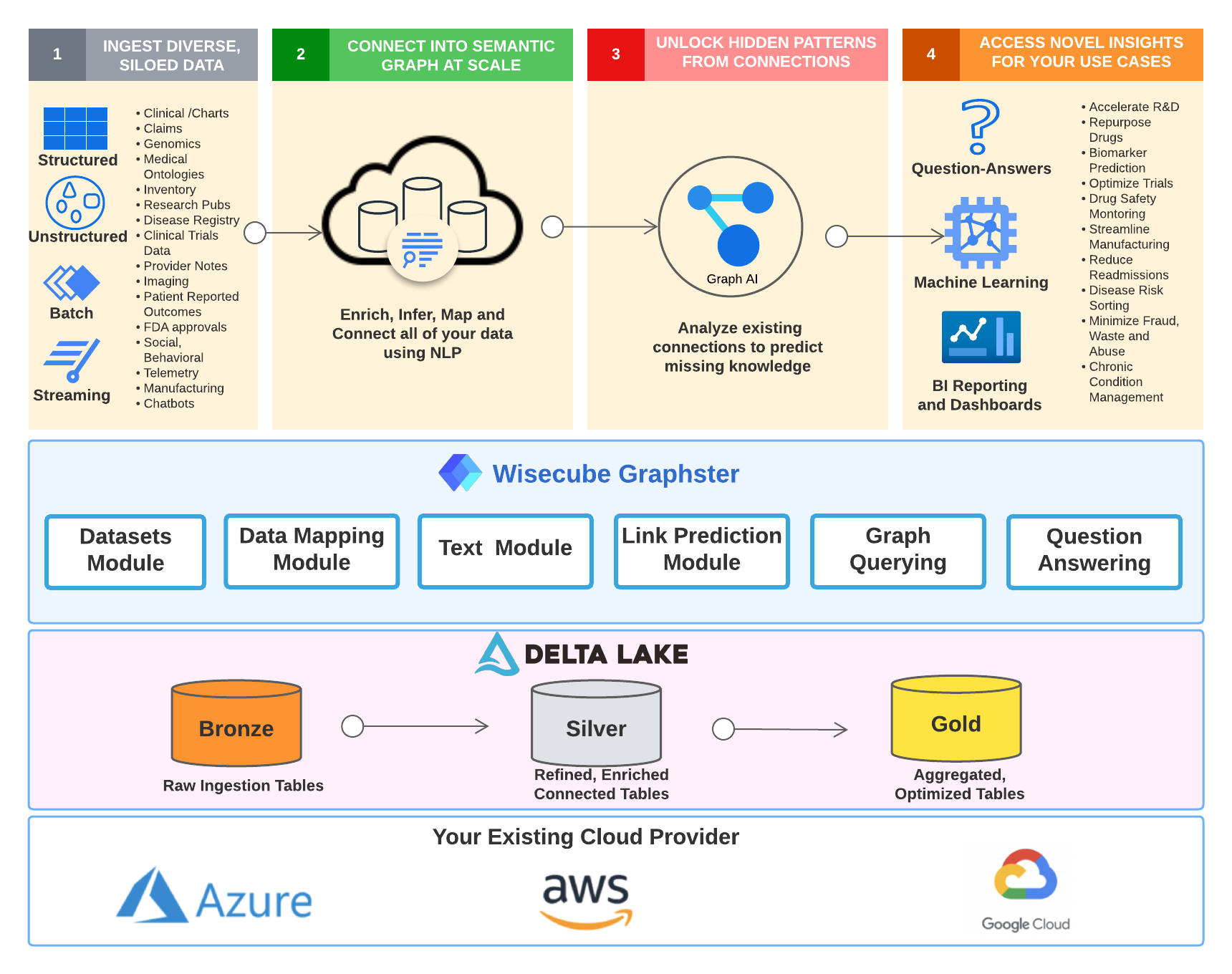
Graphster is an open-source knowledge graph library.
It is a spark-based library purpose-built for scalable, end-to-end knowledge graph construction and querying from unstructured and structured source data.
The graphster library takes a collection of documents, extracts mentions and relations to populate a raw knowledge graph, links mentions to entities in Wikidata, and then enriches the knowledge graph with facts from Wikidata. Once the knowledge graph is built, graphster can also help natively query the knowledge graph using SPARQL.
![]()
![]()
Give graphster a try!
This README provides instructions on how to use the library in your own project.
Table of contents
- Setup
- How to build a knowledge graph
- Library
- Examples
- Tutorials & Presentations
- Schedule a Demo
- Support
Setup
Clone graphster:
git clone https://github.com/wisecubeai/graphster.git
How to build a knowledge graph
Configuration
The foundation for any graphster pipeline is the configuration. This allows you to not only set important properties, but also lets you simplify the references to data elements. In building a graph, there will be many explicit references to specific data elements (e.g. URIs). Having these littered around your code hurts readability, and re-usability.
Data Sources
In order to build a knowledge graph you must be able to combine data from other graphs, structured data, and text data.
- Graph data: e.g. OWL files, RDF files
- Structured data: e.g. CSV files, RDBMS database dumps
- Text data: e.g. Document corpus, text fields in other kinds of data (>= 50 words on average)
The difficulty is that these data sets require different kinds of processing. The idea here is to transform all the data into structured data that will then be transformed into a graph-friendly format. This breaks this complex processing into three phases.
- Extraction: where we extract the facts and properties that we are interested from the raw source data
- Fusion: where we transform the extracted information into a graph-friendly format with a common schema
- Querying: where we search the data
Now that we have broken up this complex process into more manageable parts, let’s look at how this library helps enable graph construction.
Extraction
The extraction phase will generally be the most source-specific part of ingestion. In this part logic necessary for transforming the data into a format fusing into the ultimate graph’s schema.
Graph
RDF data
If the graph data comes in an RDF format then only minimal transformation will be required at this stage. This data should be parsed into tables with the Orpheus schema. The fusion step is where the IRIs, literals, etc. will be mapped to the ultimate schema.
Other Graph Formats
This data should be treated as structured data.
Structured
There are two main concerns structured data - quality and complexity. Of course, general data quality is always important in data engineering, here we are talking about a specific kind of data quality. The kind of data quality we are concerned with is completeness and consistency. What fields are null? In what formats are different data types stored (e.g. dates, floating point, booleans). Complexity is the other ingredient we must manage. Transforming a 30 column CSV into a set of triples is very different from a database with dozens of tables in 3rd normal form.
Text
In order to add text into a graph, we must extract the information we are interested into a structured format. This is where NLP comes in. This library is not an NLP library, which is why there is an abstraction layer. The idea is that the information is extracted into a structured form, so that the downstream process does not need to know what engine was used for NLP.
The minimal requirement for an NLP library to serve as an engine is named entity recognition. However, supporting syntactic parsing, entity linking, and relationship extraction can also be utilized.
The wisecube-text module is a module that acts as an interface to an NLP engine. There is an implementation with JSl
Spark NLP.
Fusion
The fusion step is where we take the structured data that has been cleaned, transformed, or extracted and map into the schema of the graph we are building. The first step of fusing new data into a graph is matching what is already there. Matching entities in the new data to entities already in the graph. The next step is mapping the kinds of relationships and properties to predicates.
Mapping to schema
There are two reasons to have custom transformations at this stage. The first is dealing differences in the conceptual design between the new data and the graph. The second is differences in the conventions recording properties.
For example, if your graph has an “author” relationship between documents and authors, but the new data has “wrote” relationship between authors and documents.
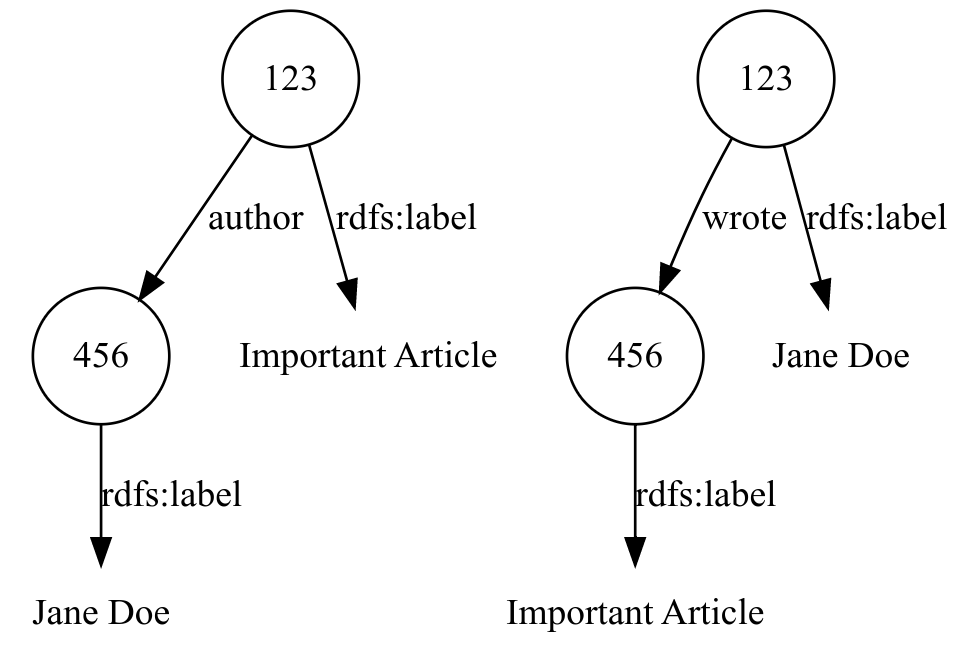
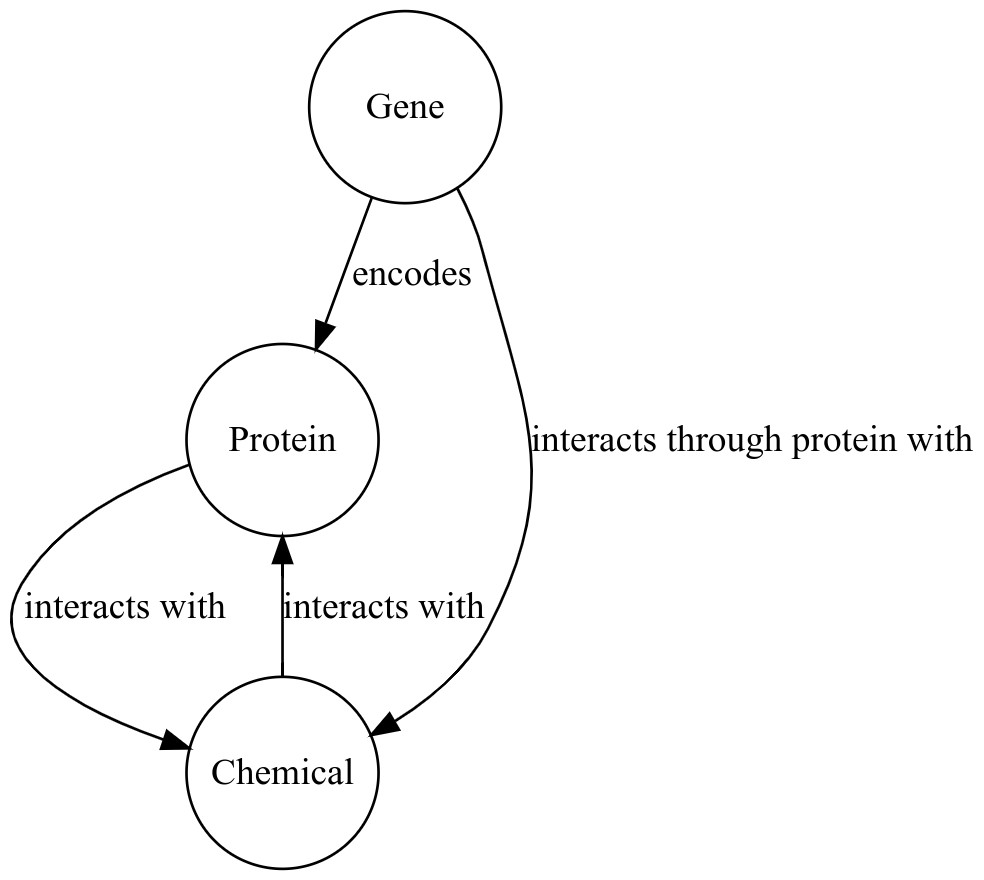
This is a simple example. The direction of the relationship needs only be reversed. Let’s consider an example with a deeper difference. Suppose the graph with which we are fusing keeps certain closely related terms as a single entity - Metonymy. For example, let’s say the graph contains proteins, genes, and chemicals. The data that is being added only has genes and chemicals. In this data, relationships between a gene and a chemical may actually represent a relationship between a protein encoded by the gene and the chemical.
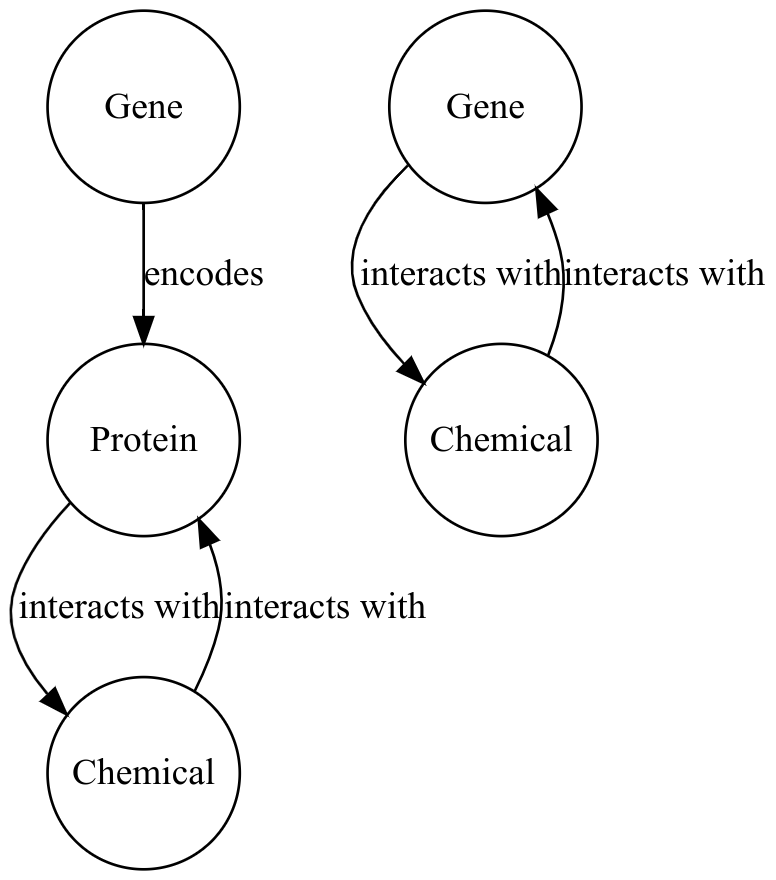
How this is mapped to the target schema depends on what other data is available as well as how flexible the schema is.
If there is additional information about the gene-chemical edges that we can use to deduce the protein (e.g. pathway
information), that can be used. Another option, if no such information is available, is to overload the
interacts with edge in the target graph to allow gene-chemical relations.
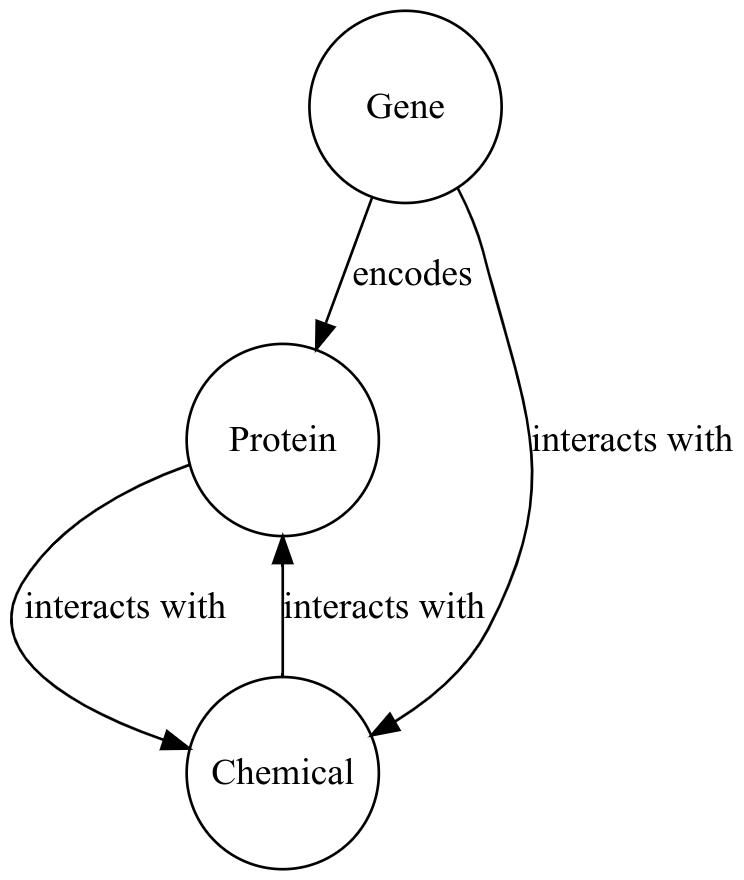
If such overloading is not possible in the target schema, then these edges can be represented with a special edge.
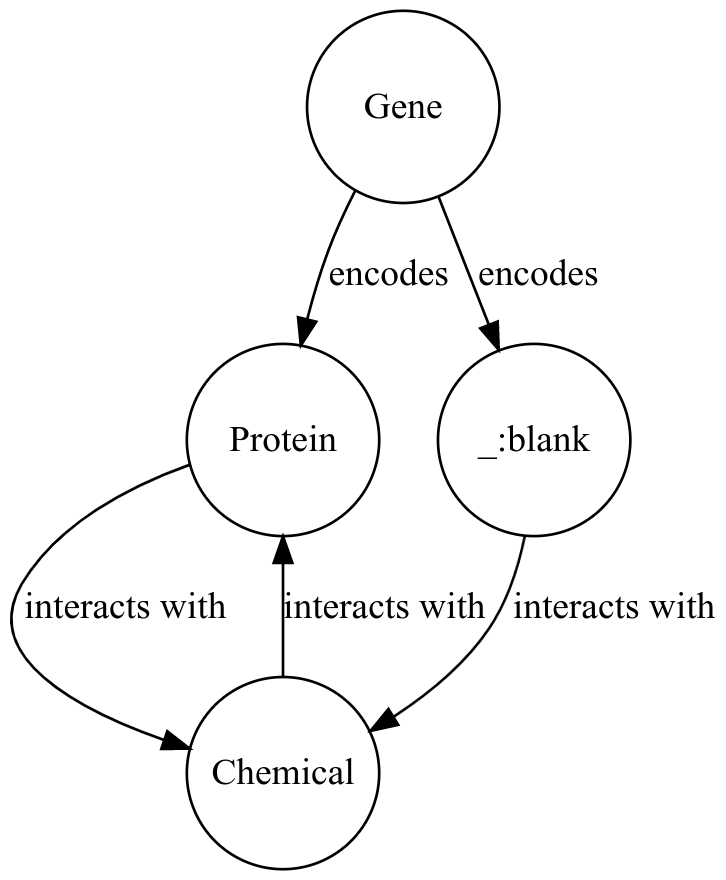
Another option is to use blank nodes, and to try and resolve them with other data.
Library
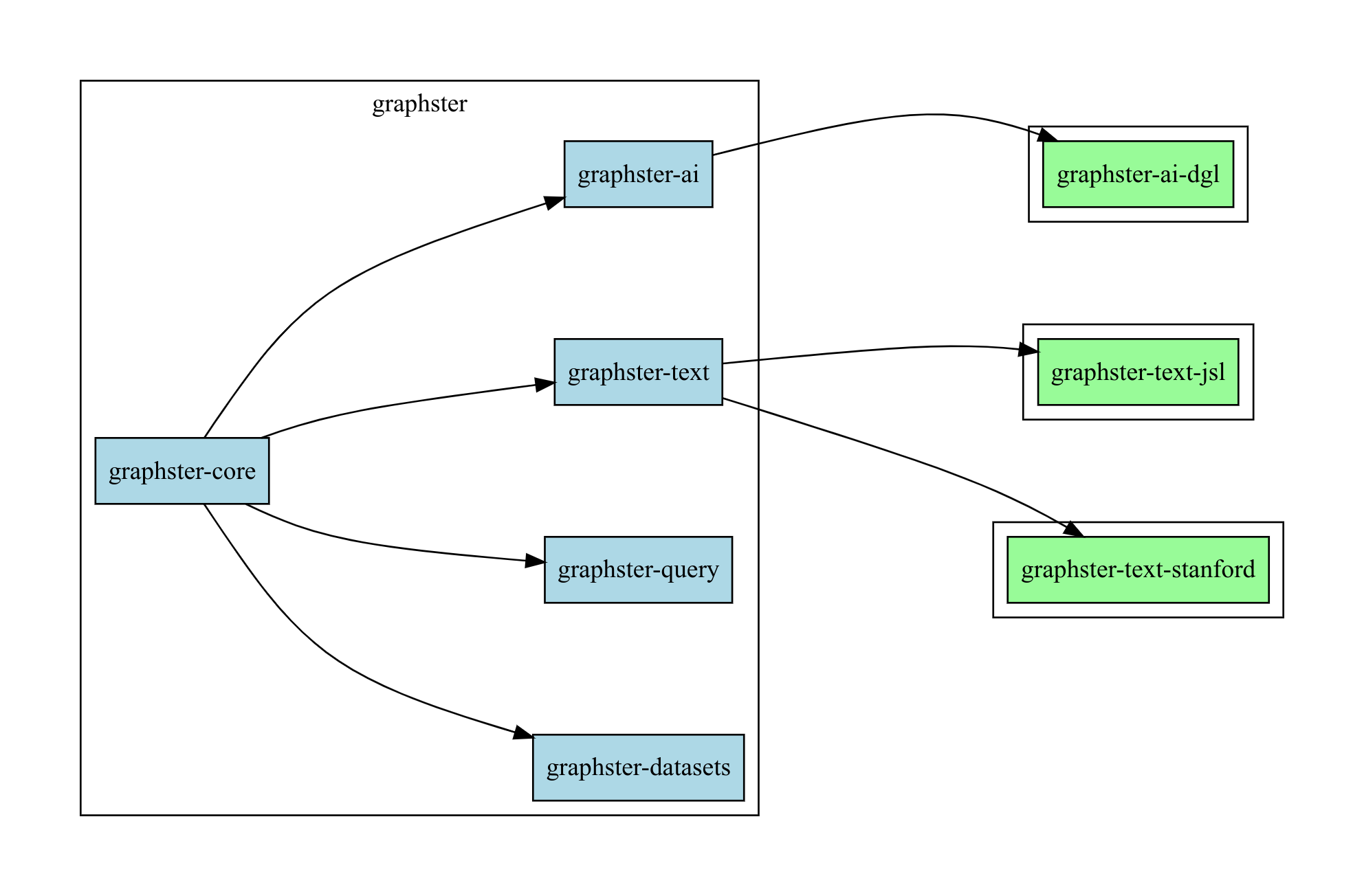
Modules
Graphster Core
The core module contains two main parts. The first is the configuration, and the second part is for processing structured data into graphs.
Graphster Datasets
The datasets module contains code for general RDF format parsing. It also contains code for setting up common datasets.
Currently, we have code for the following datasets.
- MeSH
- Clinical Trials
Graphster Text
The text module contains traits and generic components for building a text-to-graph pipeline. There will be implementation modules available NLP libraries. Currently, we are working on the reference implementation using Spark NLP.
Graphster Query
The query module is a wrapper around the Bellman project from GSK. At the moment, graphs of with more than 25 million edges will be slow.
Graphster AI
The AI module contains traits and generic components for building machine learned models on the graph. For example, link prediction, node classification, etc. Currently, we are working on the reference implementation using DGL.
Roadmap
These are the efforts we are working on at the moment.
Graphster Examples & Tutorials
We want to help people have all the knowledge they need to get started on their knowledge graphs. So we are working building out examples in the library, as well as a curriculum that will be more generally helpful in building knowledge graphs.
PyGraphster
Despite Scala be such a great language, we know that most data scientists are more comfortable in Python. So we are working on Python bindings to make Graphster more accessible.
Graphster Query optimization
The popular implementations of RDF data stores are vertically scaled. This means that if you have a large graph, you need to get a very large machine. And scaling up an existing installation can be time-consuming and expensive. It also requires that you leave Apache Spark. We want to make it easy to prepare, build, and query your knowledge graph all on Spark. To achieve this, we are working on optimizing query the data from Spark.
Graphster Subsetting
There are already many graph-structured data sets out there, like Wikidata and PubChemRDF. However, many users do not need the entirety of those graphs. Instead, they need to subset these graphs. We are building a module that will make subsetting on Spark easy.
Examples
Configuration Examples
val typeConfig = Configuration(
"predicate" -> MetadataField(URIGraphConf("http://www.w3.org/1999/02/22-rdf-syntax-ns#type")),
"trial" -> MetadataField(URIGraphConf("http://schema.org/MedicalTrial")),
"condition" -> MetadataField(URIGraphConf("http://schema.org/MedicalCondition")),
"intervention" -> MetadataField(URIGraphConf("http://schema.org/MedicalProcedure")),
)
predicate:
uri:
value: "http://www.w3.org/1999/02/22-rdf-syntax-ns#type"
condition:
uri:
value: "http://schema.org/MedicalCondition"
trial:
uri:
value: "http://schema.org/MedicalTrial"
intervention:
uri:
value: "http://schema.org/MedicalProcedure"
Structured Examples
// First we will remove the trials that are missing titles.
val removeUntitled = new SQLTransformer().setStatement(
s"""
|SELECT *
|FROM __THIS__
|WHERE ${config / "nct" / "title" / "brief_title" / "lex" / "column" getString} IS NOT NULL
|AND ${config / "nct" / "title" / "official_title" / "lex" / "column" getString} IS NOT NULL
|""".stripMargin
)
// This is the transformer that marks a column with metadata that define a triple that can be extract from the table
val nctType = new TripleMarker()
.setInputCol("nct_id") // column to be marked
.setTripleMeta(
"nct_type", // name
config / "nct" / "nct_uri" getConf, // SUBJECT
config / "types" / "predicate" getConf, // PREDICATE
config / "types" / "trial" getConf // OBJECT
)
val nctFirstDate = new TripleMarker()
.setInputCol("nct_id") // column to be marked
.setTripleMeta(
"nct_date", // name
config / "nct" / "nct_uri" getConf, // SUBJECT
config / "nct" / "date" / "predicate" getConf, // PREDICATE
config / "nct" / "date" / "date" getConf // OBJECT
)
Text Examples
Query Examples
SELECT ?cond ?condLabel ?interv ?intervLabel (COUNT(?trial) AS ?numTrials)
WHERE {
?cond mv:broaderDescriptor :D001927 . # get all immediate children of brain disease
?trial rdf:type schema:MedicalTrial . # get all clinical trials
?trial schema:healthCondition ?c . # get the condition being studied
?trial schema:studySubject ?interv . # get the intervention being studied
?c rdf:type mv:TopicalDescriptor . # limit to conditions that were linked to MeSH, and to the descriptor matches
?c mv:broaderDescriptor* ?cond . # limit to conditions that sub types of some immediate child of brain disease
?cond rdfs:label ?condLabel . # get the label for the immediate child of brain disease
?interv rdf:type mv:TopicalDescriptor . # limit to interventions that were linked to MeSH, and to the descriptor matches
?interv rdfs:label ?intervLabel . # get the label for the intervention
}
GROUP BY ?cond ?condLabel ?interv ?intervLabel # group by the immediate child of brain disease and the intervention
val query = """
|SELECT ?cond ?condLabel ?interv ?intervLabel (COUNT(?trial) AS ?numTrials)
|WHERE {
| ?cond mv:broaderDescriptor :D001927 .
| ?trial rdf:type schema:MedicalTrial .
| ?trial schema:healthCondition ?c .
| ?trial schema:studySubject ?interv .
| ?c rdf:type mv:TopicalDescriptor .
| ?c mv:broaderDescriptor* ?cond .
| ?cond rdfs:label ?condLabel .
| ?interv rdf:type mv:TopicalDescriptor .
| ?interv rdfs:label ?intervLabel .
|}
|GROUP BY ?cond ?condLabel ?interv ?intervLabel
|""".stripMargin
val results = triples.sparql(queryConfig, query).convertResults(Map("numTrials" -> "int"))
